
Kafka的选举机制
Kafka的选举机制
超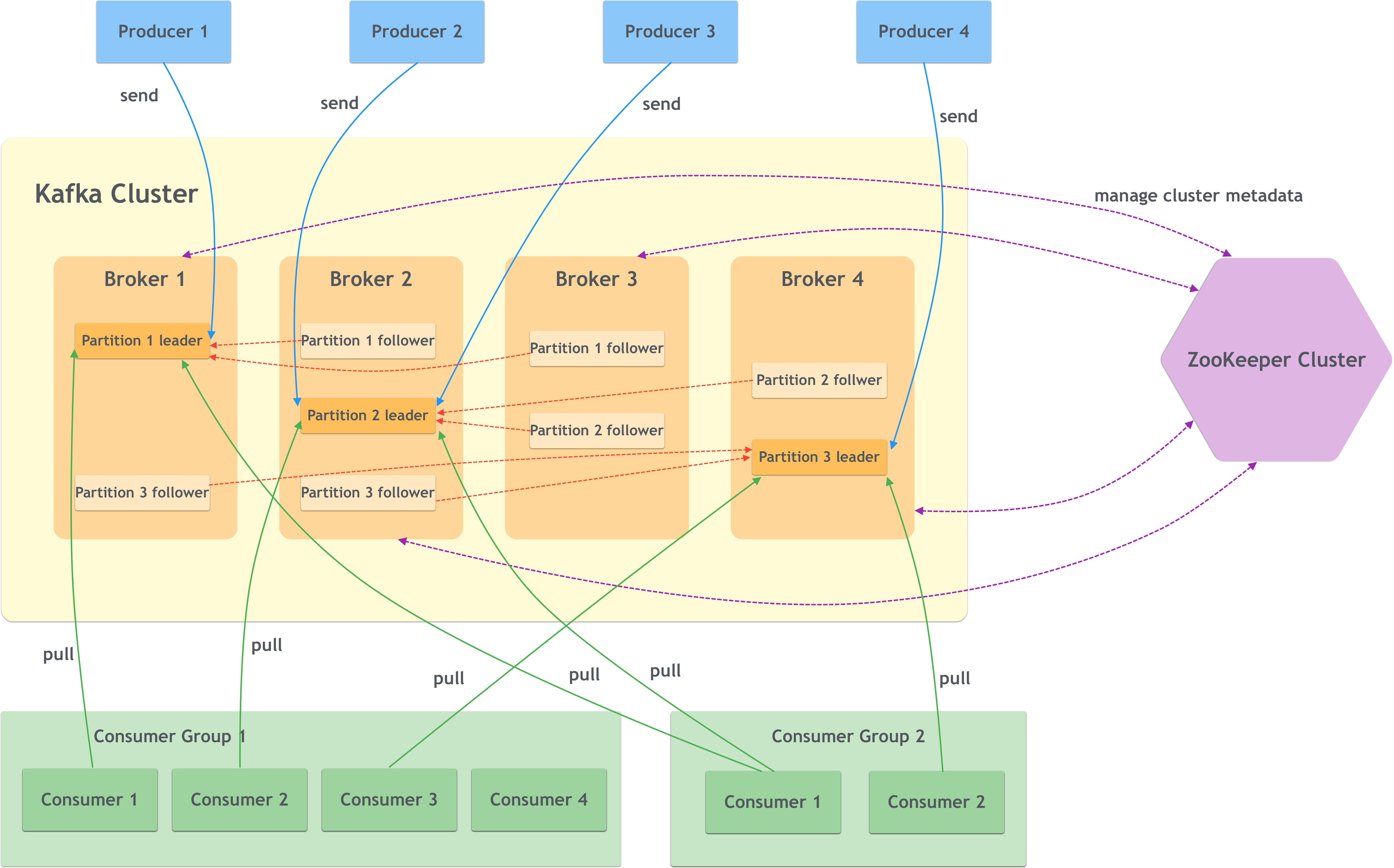
上图来自https://cloud.tencent.com/developer/article/2091555
Kafka 是一个开源的分布式消息系统,它采用了一种称为“分区”和“复制”的机制来实现高可用性和可扩展性。这个选举机制主要是用来解决分布式系统中的节点故障或者新增节点时的领导者选举问题。
在 Kafka 中,每个主题(topic)都被分成多个分区(partition),每个分区都有一个领导者(leader)和多个副本(replica)。领导者负责处理来自生产者和消费者的请求,并将数据复制到副本中。当领导者节点失效时,Kafka 需要从副本中选举出一个新的领导者来接管工作,以保证系统的可用性。
Kafka 使用的选举机制是基于 ZooKeeper 实现的,通过 ZooKeeper 协调节点之间的选举过程。每个分区的副本都在 ZooKeeper 中注册了一个临时节点,领导者节点会在该节点下创建一个顺序节点,并记录自己的 ID。当节点发生故障时,剩余的节点会竞争成为新的领导者,竞争规则通常是根据节点 ID 的顺序来决定。最终,拥有最小顺序号的节点将成为新的领导者。
这个选举机制能够有效地解决分布式系统中的节点故障问题,确保系统的高可用性和可靠性。
分区领导者选举(Partition Leader Election)
每个分区都有一个领导者,负责处理生产者和消费者的请求以及数据的复制。当分区的领导者节点失效时,剩余的副本中需要选举一个新的领导者来接管工作。
步骤:
- 当一个分区的领导者节点失效时,剩余的副本中需要选举一个新的领导者。
- 副本会在 ZooKeeper 中注册一个临时节点,表示自己可以作为领导者候选者。
- 剩余的副本中,会有一个副本发起领导者选举的请求,这个发起者通常是首先发现领导者失效的副本。
- 其他副本会在 ZooKeeper 上的目录下创建顺序节点,并记录自己的 ID 和序号。
- ZooKeeper 会根据创建顺序节点的顺序来确定选举的顺序。
- 最终,拥有最小序号的副本将成为新的领导者,其他副本成为它的追随者。
Controller 选举
在 Kafka 集群中,有一个特殊的节点称为 Controller,它负责管理整个集群的元数据和协调各个节点之间的操作。当 Controller 节点失效时,集群需要选举一个新的 Controller 节点来代替,以确保集群的正常运行。
步骤:
- Controller 是 Kafka 集群中的一个特殊节点,负责管理整个集群的元数据和协调各个节点之间的操作。
- 当当前的 Controller 节点失效时,需要选举一个新的 Controller 节点。
- 候选者(其他可用的 Broker)会在 ZooKeeper 中注册一个临时节点,表示自己可以作为 Controller 候选者。
- ZooKeeper 会根据所有候选者节点的创建时间来选举新的 Controller,通常是创建时间最早的节点。
- 选举成功后,新的 Controller 节点将开始接管原 Controller 的工作,并负责管理整个集群的状态和操作。



